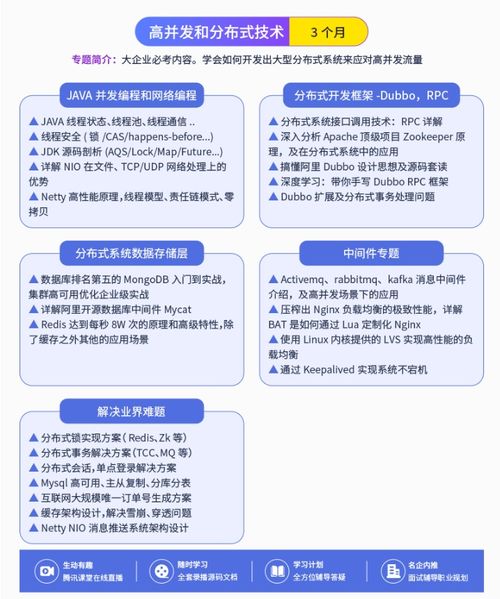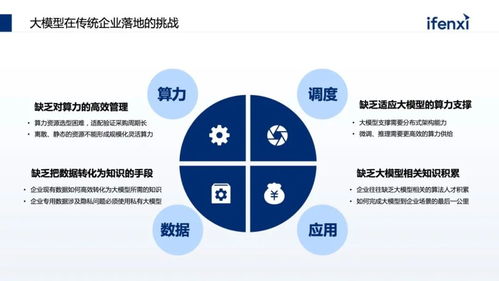
在數字化轉型浪潮中,將大模型技術與企業知識庫結合,構建智能、高效的知識管理體系,已成為眾多企業提升核心競爭力的關鍵路徑。從概念到落地,這一過程涉及復雜的技術選型、架構設計與服務集成。以下是幫助企業更好實現大模型知識庫落地的八個關鍵技術要點,涵蓋網絡技術開發與相關技術服務的核心層面。
1. 知識的高效向量化與索引構建
這是知識庫智能化的基石。需要選擇或開發適合業務場景的嵌入模型,將非結構化的文檔、數據轉化為高質量的向量表示,并建立高效的向量數據庫索引(如Milvus, Pinecone, Weaviate等),確保海量知識點的快速、精準檢索。
2. 檢索增強生成(RAG)架構的精妙設計
單純依賴大模型生成易產生“幻覺”。RAG架構通過先檢索相關知識片段,再將其作為上下文輸入大模型,能顯著提升回答的準確性與可信度。關鍵在于設計高效的檢索-排序-重排流程,并優化提示工程,讓大模型更好地理解與利用檢索結果。
3. 模型選型與微調策略
根據成本、性能、數據安全需求,合理選擇通用大模型API、開源模型或私有化部署方案。對于特定行業或企業專屬知識,采用領域數據對基礎模型進行監督微調(SFT)或參數高效微調(如LoRA),能大幅提升模型在專業領域的表現。
4. 安全、可控的網絡接口與API網關
構建穩定、安全的服務層至關重要。需設計健壯的RESTful或GraphQL API,并通過API網關實現認證、授權、限流、監控和日志管理,保障知識庫服務的高可用性與訪問安全,便于與企業現有系統(如OA、CRM)集成。
5. 多源異構數據的智能接入與處理流水線
企業知識散落在文檔、數據庫、郵件、IM工具等多個源頭。需要建立自動化的數據管道,支持PDF、Word、Excel、網頁、數據庫等多種格式的解析、清洗、分塊與元數據提取,實現知識的持續、低維護成本更新。
6. 上下文長度管理與對話狀態維護
大模型有上下文窗口限制。技術實現需包含智能的上下文窗口管理策略,如關鍵信息摘要、歷史對話選擇性保留等,在長對話或多輪交互中維持連貫性與準確性,提升用戶體驗。
7. 全面的可觀測性與持續優化體系
部署監控系統,追蹤查詢延遲、token消耗、回答準確率、用戶反饋等關鍵指標。建立基于人工評估或自動化測試的迭代閉環,持續優化檢索策略、模型提示和排序算法,驅動知識庫性能與效果的不斷提升。
8. 專業化技術服務與運維支持
落地不僅是技術開發,更是持續服務。企業需要或應構建涵蓋架構咨詢、私有化部署、性能調優、安全審計、故障響應和員工培訓的技術服務能力,確保系統穩定運行并創造業務價值。
成功落地大模型知識庫是一個系統工程,需要將這八個技術要點有機融合。企業應結合自身業務規模、技術積累和數據特點,制定循序漸進的實施路徑,優先解決核心業務場景的痛點,并構建起持續演進的技術與服務能力,最終讓知識庫成為企業智慧的核心載體與效率引擎。